分布式计算 定义: 分布式计算是研究把一个需要非常巨大的计算能力解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把各部分的计算结果合并起来得到的最终成果(分而治之)。 分布式...
”Impala SQL分析 大数据 分布式计算 内存计算“ 的搜索结果
从零开始讲解大数据分布式计算的发展及Impala的应用场景,对比Hive、MapReduce、Spark等类似框架讲解内存式计算原理,基于Impala构建高性能交互式SQL分析平台 课程亮点 1,知识体系完备,从小白到大神各阶段读者均...
Spark是一种基于内存的、用以实现高效集群计算的平台。Spark有着自己的生态系统,但同时兼容HDFS、Hive等分布式存储系统,可以完美融入Hadoop的生态圈中,代替MapReduce去执行更高的分布式计算。
Hadoop/Spark是源自头部互联网企业的重型解决方案,适合需要有超大规模集群...这种情况下,轻量级的大数据计算引擎SPL是首选,投入很低的成本,就可以做到技术轻、使用简便,而且还能提高开发效率、达到更高的性能。...

总结很不错,就转过来了,原博文:http://blog.csdn.net/recommender_system/article/details/42024205 一、高性能计算 目前自己知道的高性能计算工具,如下所示: Hadoop:Hadoop的框架最核心的设计就是:HD...
什么是分布式计算框架?分布式计算框架就是为分布式系统设计的计算模型和开发环境。大数据时代的到来让越来越多的人都成为数据处理方面的专家、工程师或公司高管。作为一个架构师、程序员或者项目经理,掌握分布式...
通常使用分布式数据处理提高数据规模、使用 内存数据进行计算过程缓冲和优化。本平台主要采用Spark SQL结合高速缓存Redis的技术来实现。Spark SQL作为大数据的基本查询框架,Redis作为高速缓存去缓存数据热区,减小...
本文首发微信公众号:二进制社区,转载请联系: [email protected]</h3></br><!doctype html><div class="lake-content-edito
深入了解大数据计算模式
标签: 大数据
批处理计算主要解决针对大规模数据的批量处理,也是我们日常数据分析工作中非常常见的一类数据处理需求。 MapReduce是最具有代表性和影响力的大数据批处理技术,可以并行执行大规模数据处理任务,用于大规模数据集...
分布式计算平台Spark:基础入门 20201216 一、课程 大数据组件 分布式存储 Zookeeper:利用分布式存储系统实现小的核心数据的存储(加紧复习) 抓紧复习 HDFS:离线大数据文件系统数据存储(加紧复习) ...
Apache Spark是一种快速、通用、可扩展的...Spark的主要优点在于:易于使用、分布式计算能力强、丰富的工具支持和丰富的应用案例。本文将从如下三个方面对Spark进行讲解:基础知识、编程模型和应用场景。什么是Spark?
近几年来,随着互联网技术的飞速发展,大数据技术也呈现爆炸性增长,以数据采集、处理、分析等方式产生海量的数据。如何有效利用大数据的价值变得越来越迫切,因此出现了大数据相关的云服务提供商如亚马逊AWS、微软...
大数据分布式查询引擎–presto 一.名词解释: •Coordinator: Presto主角色,单一节点,负责接受客户端请求,SQL语句解析,生成执行计划,管理worker节点; •Worker: presto实际处理处理运行任务的节点,从...

bigdata


一、前言大数据技术从诞生到现在,已经经历了十几个年头。市场上早已不断有公司或机构,给广大...第一,大数据分析相关,针对海量数据的挖掘、复杂的分析计算;第二,在线数据操作,包括传统交易型操作以及海量数据...


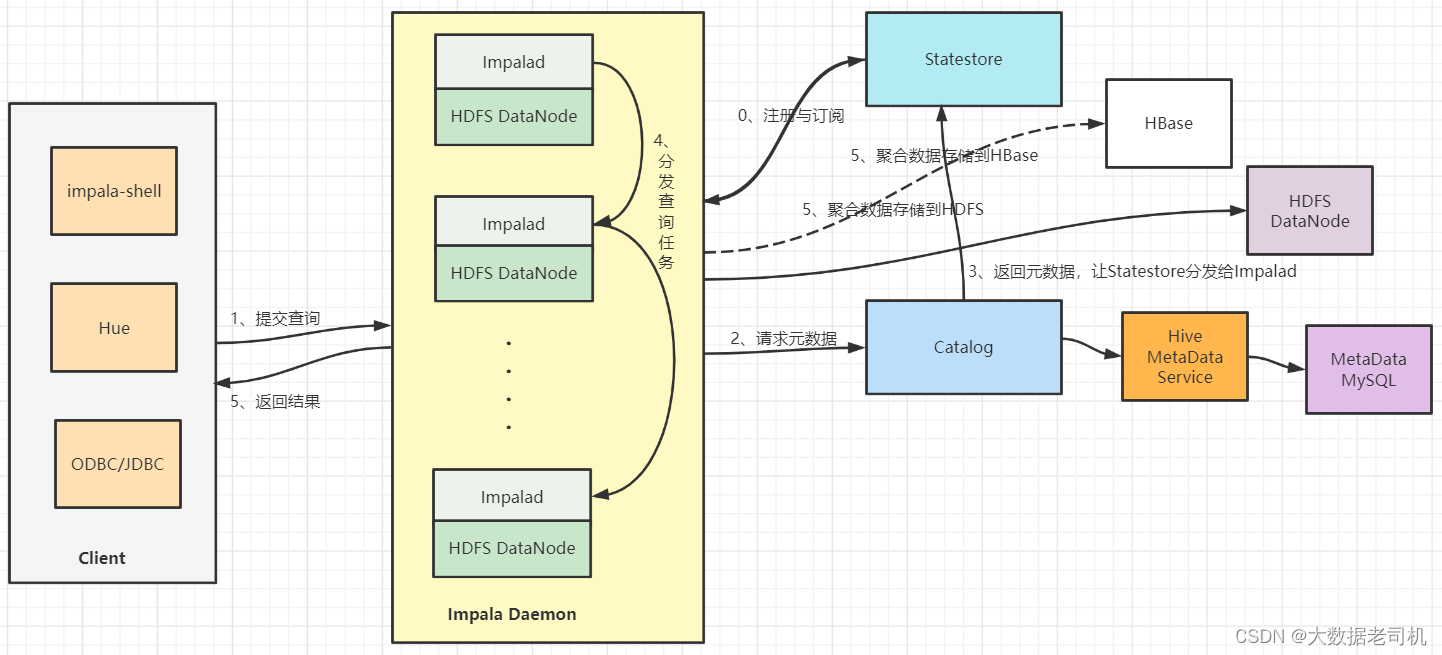
(2)基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点; (3)是CDH平台首选的PB级大数据实时查询分析引擎。 1.2 Impala优点 (1)基于内存进行计算,能够对PB级数据进行交互式实时查询和分析...
大数据的“大”是相对而言的,是指所处理的数据规模巨大到无法通过目前主流数据库软件工具,在可以接受的时间内完成抓取、储存、管理和分析,并从中提取出人类可以理解的资讯。 业界普遍认同大数据具有4个 V...

15、Impala(分布式SQL引擎) Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是...
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地